DataOps Principle #15: Quality is Paramount
In my last entry I explained how to update a dataflow in the Power BI Service and have it automatically check-in those changes to source control. Now that we have the code in Git, what’s next?
Here is where we turn to the principle of “Quality is Paramount”:
DataOps Principle #15 - Analytic pipelines should be built with a foundation capable of automated detection of abnormalities and security issues in code, configuration, and data, and should provide continuous feedback to operators for error avoidance.
Dataflows are the epitome of an analytic pipeline, and therefore we must create a foundation for testing for issues with the code and the data in an automated fashion.
But we are challenged by:
The lack of a built-in testing tool within Power BI. In Part 4 we used DAX Studio as an external tool to test the datasets. However, that is not an option with dataflows because you cannot query the output of a dataflow with DAX.
The lack of an easily accessible testing pattern within Power BI for data analysts. As a self-service business intelligence tool, Power BI’s largest user base are data analysts, not developers/computer scientists who are familiar with writing code that tests code. Case in point, when you pass the PL-300 exam, you become a certified Power BI Data Analyst and not a certified Power BI Developer.
Looking For A Solution
This led me to look around for some options to mitigate these challenges. I came across an article written at endjin by James Broome. In it he explained that the team at endjin used SpecFlow to automate testing. SpecFlow implements a behavior driven development approach that uses the Gherkin Language to define tests through written narratives and acceptance criteria (see example below).

Figure 1 – Example of a test written with the Gherkin Syntax courtesy of Wikipedia
Within SpecFlow, tests are written in .NET and executed using .NET. Sure, I love .NET, but I was looking for a way to execute the tests so the data analyst could build/run the tests in Visual Code on their computer with very little coding; furthermore, they could also run the same tests in Azure DevOps or GitHub Actions to automate testing when dataflows are updated.
This lead me to PowerShell (yes, I know it runs on .NET), and version 4 of Pester which is a test runner that implements the Gherkin Language.
A Potential Solution
With version 4 of Pester, the sentences written in the Gherkin syntax (which you can think of as plain English) are a “.feature” file and look something like this:
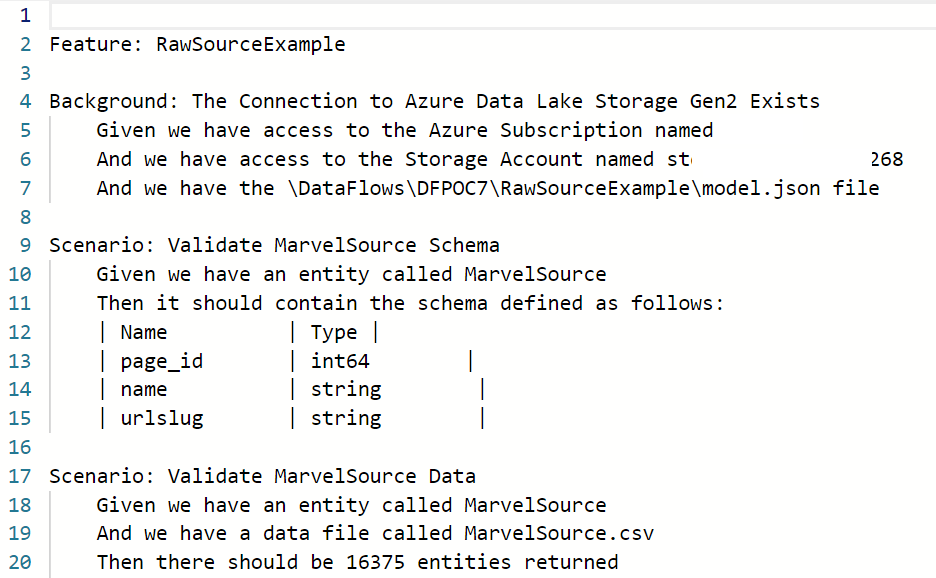
Figure 2 – Example of a test written with the Gherkin Syntax in Pester
Each sentence can be backed by a “.steps.ps1” file written in PowerShell where a function executes a sentence based on its intent. Therefore, starting from line 4 in Figure 2 you could have a set of corresponding PowerShell functions that:
Lines 4-6 - Verify a connection to the Azure Data Lake Storage can be made, and you have access to the storage account and model.json file.
Lines 9-15 - Inspect the contents of the model.json file in source code, verify it has an entity (table) and that its schema contains a predefined set of columns and format.
Lines 17-20 - Reach out to the Azure Data Lake Storage and verify the number of records ingested.
This method is quite powerful in that if you constuct the “.steps.ps1” files correctly, many of the tests a data analyst could write in plain language (“.feature” file) could be executed with little need to look at the PowerShell code written in the “.steps.ps1” file.
Running the Tests
So now you may be thinking, alright this Pester/Gherkin thing could be quite useful, but what is required to run these tests? Well, if you already bought into Part 20, you have VS Code (free), and you’ve got the project cloned to your local machine with Git (free), then running the tests just involves running “Invoke-Gherkin” in the terminal. It will run through all the tests in your project and tell you what has passed or failed.
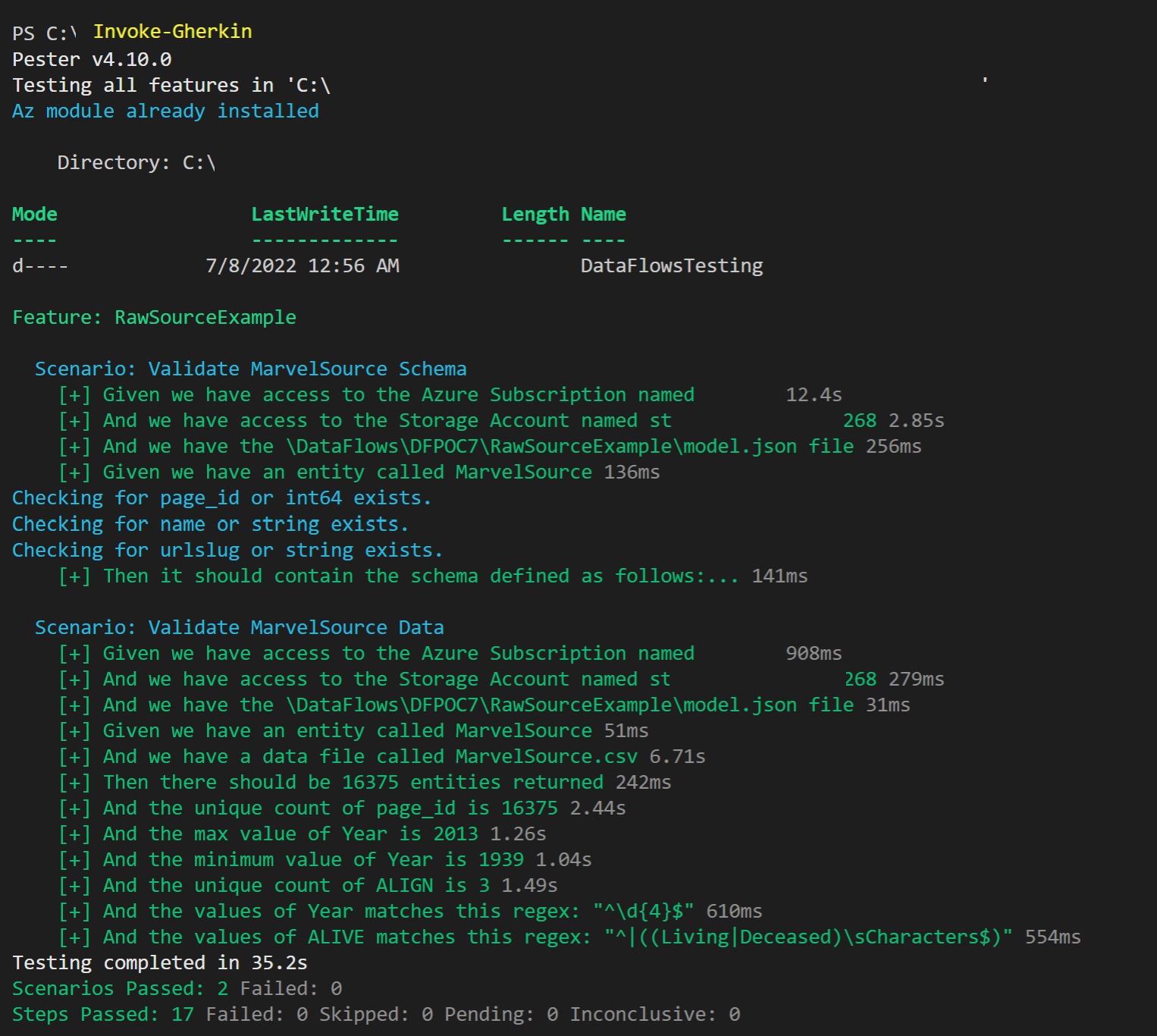
Figure 3 – Example of tests executed in VS Code terminal with Pester
Oh, and even better, these tests can automatically run in Azure DevOps with the same “Invoke-Gherkin” statement. I’ll save that for an upcoming post as it involves some level of orchestration (hint, hint) to explain.
Best Practices
For those looking to test their dataflows, I have some best practices that should help mitigate errors going to production.
Have a Test Dataset – In order to test effectively you need to have a known underlying dataset to validate your Power BI dataflow. For example, if you import a SQL table, adjust the query to a specific period of time. The goal is to have a static set of data to work with, so the only variables that would change during a test is the code you or your team has changed in the dataflow.
Leverage Parameters in your Dataflow – Eventually when you want to transition from the test dataset to a staging or production environment you don’t want to have to manually update the code. Parameters can allow you to manage connection details in the Power BI Service between your environments (dev/test/prod).
Test the Schema – For each table (entity) produced by a dataflow make sure the columns match the names and formats expected. Unexpected schema changes are a common cause for broken analytic pipelines, so this type of test is a must for me.
Test the Content – Columns in each table produced by a dataflow should meet some expectation you can test, such as:
- The uniqueness of values in a column (no duplicates).
- The min and max values for an numeric column.
- A column of strings match a regular expression.
- A column has no blank values.
Sharing The Proposed Solution
With the Proposed Solution and Best Practices in mind, I’ve shared instructions on how to run these type of tests with a sample dataflow on GitHub. My hope is that you can leverage these samples to start to build a suite of dataflows backed by source control, and tested using a framework which data analysts can use.