DataOps Principle #4: It’s a team sport
Despite the negativity and seedy underbelly that comes with social media, it does foster an environment for developers and practitioners of technology to collaborate. I spend so much of my time consumed with the work and environments I operate under that I could easily miss the new technologies, techniques and ideas that could spur new opportunities for my team and I.
DataOps Principle #4: Analytic teams will always have a variety of roles, skills, favorite tools, and titles. A diversity of backgrounds and opinions increases innovation and productivity.
Often, we think of a team as the folks who we work with or contract with day-in and day-out. While true, I think of the Power BI community as a part of my team as well. Countless blog articles, forums, videos, and conferences have sparked better ways for my team and I to deliver Power BI solutions. And when I’ve offered some ideas, the feedback I have received has been just as valuable and has got my wheels turning (and I admit these wheels need a little caffeine and sugar to get moving these days).
A common theme in the feedback has been questions/thoughts on how to bring DataOps to dataflows. Full disclosure, I am new to dataflows as I have had other products available to my team and I for producing curated datasets and dimensions for Power BI (e.g., Data Factory, SSIS), but I can see the immense value dataflows bring to the enterprise by promoting reuse, standards for data, and the convenience in having them as part of the Power BI platform.
So, the first thing to tackle with dataflows was the same issue we needed to tackle with Power BI Desktop, how do I get this low-code’s underlying code into source control as seamlessly as possible? If I could do that, all the testing, continuous integration (CI), and continuous deployment (CD) could be easier to implement.
And that was a bit of a challenge because:
1) Dataflows are built in the Power BI service; thus, the code sits in the cloud and is not immediately accessible to Git.
2) You can export dataflow code but the steps are manual (done in the browser). You can script the export with PowerShell but how do you know when to run the script? Relying on someone to remember to export the dataflow and push to source control is not really optimal.
With those challenges in mind, I scoured the content out there in the community and started to form a proposed solution. Figure 1 provides an illustration of my first pass.
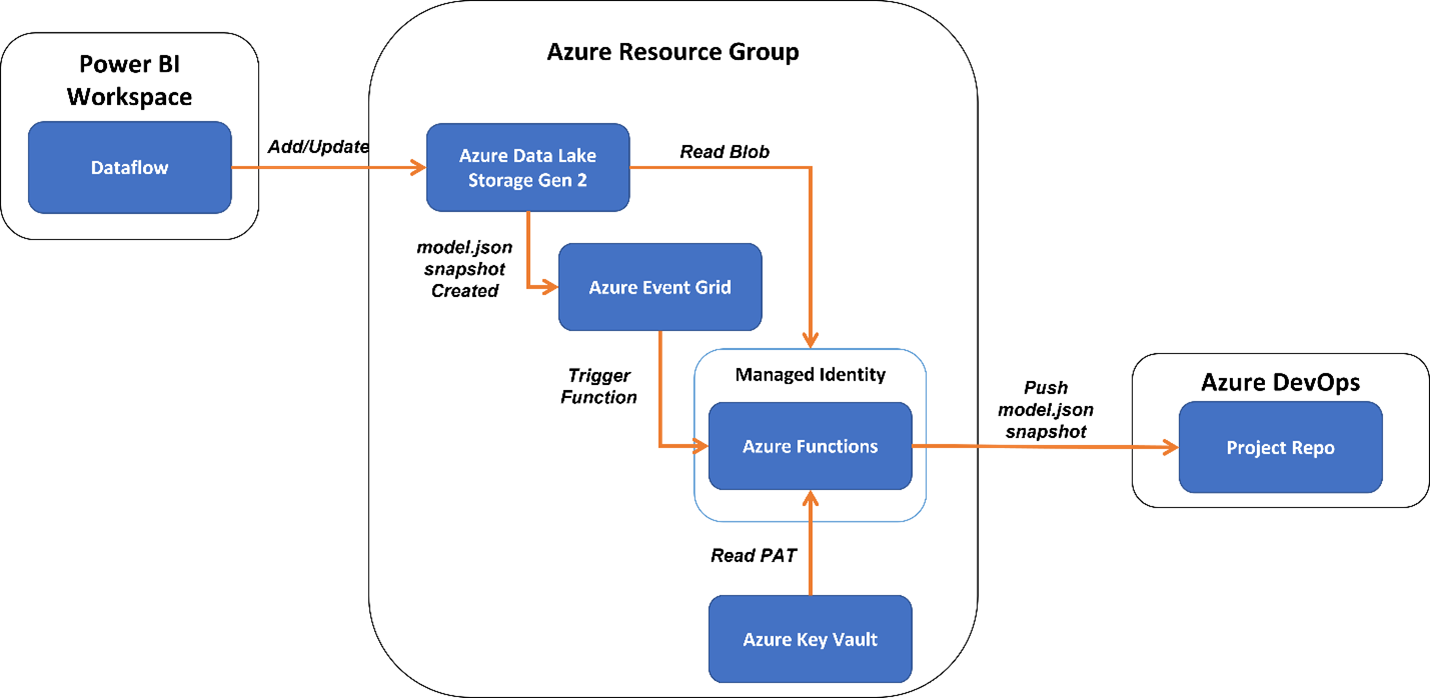
Figure 1 – Proposed solution for automatically storing a dataflow into source control (Git)
Here are the components of the proposed solution:
1) Azure Data Lake Storage Gen2 (Bring Your Own Data Lake) - Thanks to a feature that debuted in May 2021, Power BI can store dataflows and the contents (partitions) it builds in your own data lake for an individual workspace. This avoids having to convince your Power BI admin to provide access to a tenant-level data lake and the security considerations that may make the thought of Bring Your Own Data Lake (BYOD) impractical. With BYOD, dataflows and content are stored as shown in Figure 2.
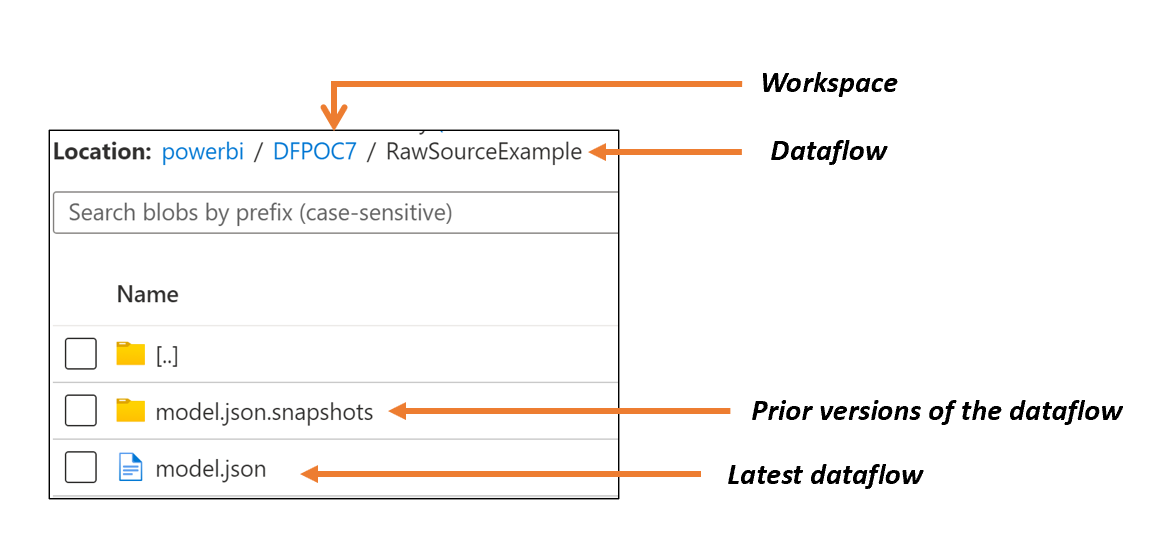
Figure 2 – Structure of dataflows in Azure Data Lake Storage Gen2
The snapshots folder is the key here. Every time a dataflow is created/updated, a version of it is saved into this folder with a timestamp and the latest version is saved in the model.json file located in the parent folder If we can flag when new entries in the snapshot are created and automatically move the new entry to Git, we can capture every version and avoid a potential race condition on the model.json file. The race condition would involve the time period between this solution receiving notice that model.json has changed and the solution extracting the contents of model.json from the data lake. During that time period model.json may have changed because of another save to the dataflow occurred. Thus, we risk missing a version of the dataflow to save to Git.
2) Event Grid - This component of Azure allows us to monitor a data lake for new snapshots to appear and issue a notice (topic) in a publisher/subscription pattern. That way Event Grid provides a reliable messaging system to trigger the next component.
3) Azure Functions - This component has a function triggered by an Event Grid subscription that does the yeoman's work:
- Grabs the content of the snapshot from the data lake,
- Issues messages to Azure DevOps to appropriately get the reference id so it can then,
- push the snapshot file to Git.
4) Azure Key Vault - For the Azure Function to interact with Azure DevOps it needs a Personal Access Token with read, write, manage permissions to the code in Git. Microsoft recommends using Key Vault instead of Application Settings to store this sensitive information.
5) Managed Identity - This is the glue that holds a lot of this solution together. The Azure Function needs access to the data lake and the key vault and by making the Azure Function a managed identity you can grant access to each component without the need for maintaining a new set of passwords (and we all have too many passwords to maintain these days).
Sharing The Proposed Solution
In the spirit of make it reproducible I have scripted the installation on this proposed solution and made it available on GitHub. Let me know what you think on LinkedIn or Twitter.
From my own reflection there are some things that I think could make the solution better:
1) Durable Functions - I tried to make the proposed solution use the consumption license model to keep costs down, but a Durable Function could make the Azure Function more responsive to changes and allow for function chaining which could make the custom code more manageable (and easier to test).
2) Easier setup for between the workspace and data lake connection - During the course of setting this solution up, the “Access Denied” message from connecting a Power BI workspace to the data lake befuddled me. With the same permissions on the data lake it could take between 1 and 3 tries (without any manual permission changes) before the connection was established. I even put in a pull request in the hopes that the instructions could be better. I would like to see this installation step more automated and reliable.
3) Automated PAT token generation – This capability is available but is still in preview. I would prefer to automate this installation step when it becomes generally available or figure out a better way to extend the Function’s managed identity permission to Azure DevOps and get rid of the PAT Token altogether.
What do you think could make it better? Any thoughts on making this scalable?
A team effort
I would not have accomplished anything workable or anything so quickly without the tech. communities’ efforts to enlighten and inspire. So, it is time to say thanks to the team:
Matthew Roche for the series on dataflows (a must read and watch)
Olivier Miossec for making it easier for me to get PowerShell to work with Azure DevOps.
Nicola Suter for guidance on integrating PowerShell modules in Azure Functions.
Wojciech Lepczyński for teaching me how to work with Azure Functions using the Azure CLI.
And those who keep the Microsoft documentation up-to-date with articles on ADLS Gen2 and Power BI and tutorials on using Azure Event Grid.
In my next article we’ll continue Bringing DataOps to dataflows… stay tuned team.